AI Datasets Explained: Types, Challenges, and Why Quality Matters
- 3 days ago
- 8 min read

Even the most advanced AI is useless without one thing, good data. It’s the difference between a model that predicts with confidence and one that stumbles on the basics.
AI datasets are collections of information, such as images, text, audio, or video, used to train and improve artificial intelligence models, enabling them to recognize patterns, make decisions, and generate outputs.
From chatbots that understand natural language to medical AI that spots early signs of disease, every breakthrough starts with the right dataset. As AI moves deeper into daily life, the quality, diversity, and ethics of these datasets will decide whether we build systems we can truly trust.
What You Will Learn in This Article
Understanding AI Training Datasets: The Bedrock of Machine Learning
When people talk about AI datasets, they’re referring to carefully gathered collections of information that help AI systems learn.
Think of them as the “study materials” for artificial intelligence, without them, an AI model has nothing to practice on, no examples to follow, and no foundation to build its “understanding” of the world.
The Many Forms AI Datasets Can Take
An AI training dataset can include just about any kind of data: images of cats and dogs, customer service chat transcripts, audio recordings of spoken language, even satellite images of farmland.
These can be labeled (with extra information like “this is a dog” or “this email is spam”) or unlabeled (where the AI has to figure things out itself).
Why the Quality of Data Changes Everything
The purpose of these datasets is simple but powerful: they allow AI to recognize patterns, classify objects, predict outcomes, or even generate new content.
Just like a chef can’t make a meal without ingredients, an AI model can’t perform without high-quality, relevant data. The richer and more representative the dataset, the more capable the AI becomes.
Types of AI Datasets and How They Shape Learning
Not all AI datasets are built the same way. Depending on the learning approach, the structure of the data changes and so does the way the AI uses it.
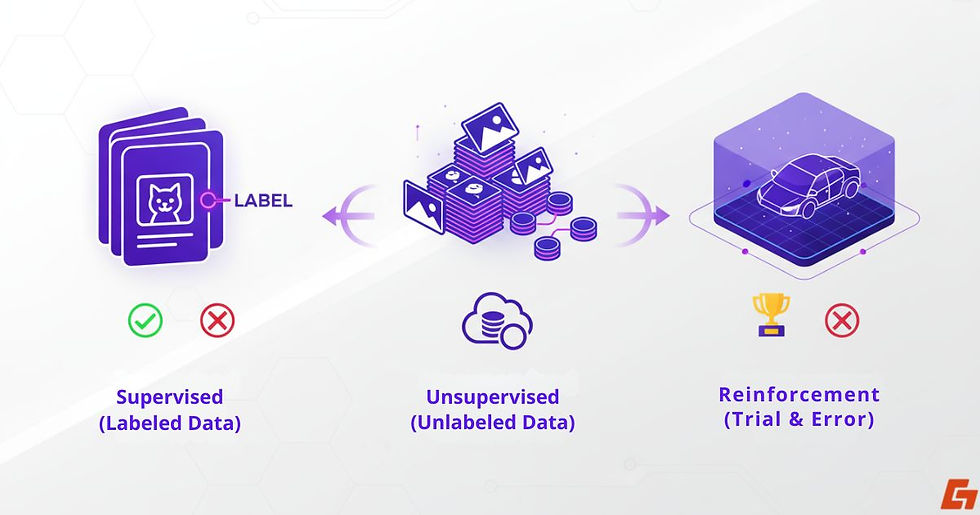
Supervised Datasets: The AI Flashcard Method
These are like flashcards for AI. Every example comes with both the input and the correct output. An image might have the label “cat,” or a sentence might be marked as “positive sentiment.”
This structure gives the AI clear right-or-wrong feedback as it learns. Popular supervised datasets include ImageNet (for image classification) and COCO (for object detection).
Unsupervised Datasets: Letting AI Discover Patterns
Here, there are no labels at all. The AI receives raw information and has to uncover patterns on its own. Imagine dumping thousands of photos into a folder without naming them, the AI figures out which images are visually similar or which groups naturally form.
Large-scale resources like Common Crawl give models this kind of raw, unlabeled data.
Reinforcement Learning Datasets: Learning by Trial and Error
This type takes inspiration from trial-and-error learning. Instead of static labels, the AI gets feedback in the form of rewards or penalties based on its actions.
For example, in a simulated environment, a self-driving car model might earn a “reward” for staying in its lane and a “penalty” for running a stop sign.
Why These Categories Matter
Understanding these categories helps explain why some AI systems can identify a picture instantly while others are designed to learn strategy, adapt, and improve over time.
Why AI Datasets Can Make or Break Your AI Model
Here’s the truth: the quality of AI datasets can make or break an AI project. You could have the most advanced algorithm in the world, but if the data is flawed, biased, or incomplete, the AI’s output will reflect those problems.

Garbage in, garbage out, it’s not just a saying; it’s a hard reality in AI development.
When Bias in Data Becomes a Real-World Problem
For example, if a dataset used to train a facial recognition system contains mostly images of lighter-skinned individuals, the resulting model will likely perform poorly for people with darker skin tones. That’s not just a technical issue, it’s an ethical one.
The ripple effects of biased AI can impact hiring decisions, loan approvals, and even law enforcement.
The Power of Diverse, Well-Curated Datasets
On the flip side, diverse and well-curated datasets enable AI to generalize better, adapt to new situations, and make accurate predictions.
They also reduce the risk of overfitting, where an AI memorizes its training data but fails when facing new, unseen examples.
The Real Takeaway
The takeaway? Building better datasets isn’t optional; it’s central to creating AI that works fairly and reliably in the real world.
The Role of Data Labeling and Annotation in AI Success
When working with supervised AI datasets, labeling is where the magic really happens. It’s the process of adding meaningful tags or metadata to raw information so the AI knows exactly what it’s looking at.

For instance, a dataset of emails might be labeled as “spam” or “not spam.” In computer vision, an image of a street might have bounding boxes drawn around pedestrians, traffic lights, and vehicles.
Human vs. Automated Annotation
Labeling can be done by human annotators, who often work through specialized platforms, or by automated tools that use pre-trained models to speed up the process.
Humans tend to be more accurate, but automation can handle massive datasets far faster. The trade-off? Speed sometimes comes at the cost of precision.
How Labeling Quality Shapes AI Accuracy
The quality of annotation directly shapes how well an AI model performs. If a label is wrong often enough, the AI will confidently give incorrect answers later.
In practice, experts track this through inter-annotator agreement, checking how consistently multiple annotators tag the same data. Low agreement rates flag potential issues early, preventing “mislearned” patterns that are hard to correct once embedded.
Common Challenges That Can Undermine AI Datasets
Despite their importance, AI datasets aren’t without problems. In fact, the bigger and more complex they get, the more issues can creep in.
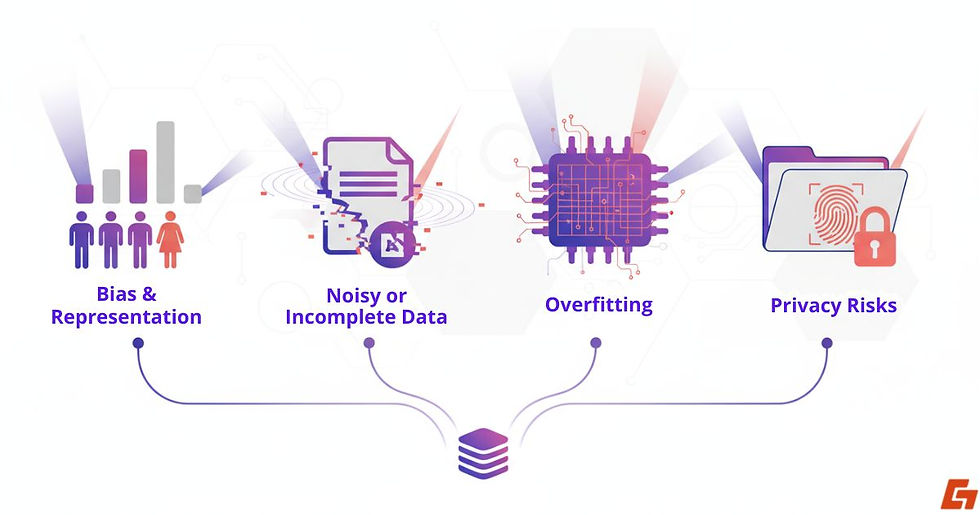
Bias and Representation Gaps
One major challenge with AI datasets is bias in representation. If the dataset doesn’t reflect a balanced mix of demographics, such as gender, ethnicity, or geography, the AI will likely carry those biases into its predictions.
Professionals often measure this by comparing the dataset’s demographic breakdown to real-world statistics. Significant gaps here can lead to skewed results and reduced accuracy for underrepresented groups.
Data That’s Noisy or Incomplete
Another problem is noisy or incomplete data, where information is either inaccurate, inconsistent, or missing key details. These gaps can cause AI to misinterpret patterns or overlook important signals.
Overfitting: When AI Memorizes Instead of Learning
Overfitting is another pitfall. This happens when the AI becomes too familiar with the training set, memorizing instead of truly learning, and then struggles to perform on new data.
Privacy Risks in Sensitive Domains
Then there’s the matter of privacy, using sensitive information like medical records or biometric data can raise ethical and legal concerns, especially under laws like GDPR or HIPAA.
The Bigger Picture
These challenges highlight why building good datasets isn’t just a technical task, it’s also a legal, ethical, and societal responsibility.
How AI Models Learn from Datasets
Training an AI model with AI datasets is a structured process. It starts with splitting the data into three groups: the training set, the validation set, and the test set.

The training set is where the AI learns; the validation set helps fine-tune parameters; and the test set checks how well the model performs on completely unseen examples.
The Learning Loop: Predict, Compare, Adjust
During training, the model makes predictions, compares them to the correct answers (if available), and adjusts its internal settings, called weights, based on the errors.
This loop continues until the model reaches acceptable accuracy. Evaluation metrics like precision, recall, and F1 score depend heavily on the dataset used.
Why Dataset Diversity Determines Success
If the dataset is diverse and representative, the AI will be better equipped to handle real-world variability. But if the dataset is narrow or skewed, even the most sophisticated algorithms can falter outside of their comfort zone.
The Core Lesson
In short, the data is the foundation and the foundation determines the strength of the entire structure.
The Push for Better, More Ethical AI Datasets
In recent years, the conversation around AI datasets has shifted from “How big is it?” to “How good is it?” Size still matters, especially for deep learning, but quality, diversity, and transparency have become the real benchmarks.
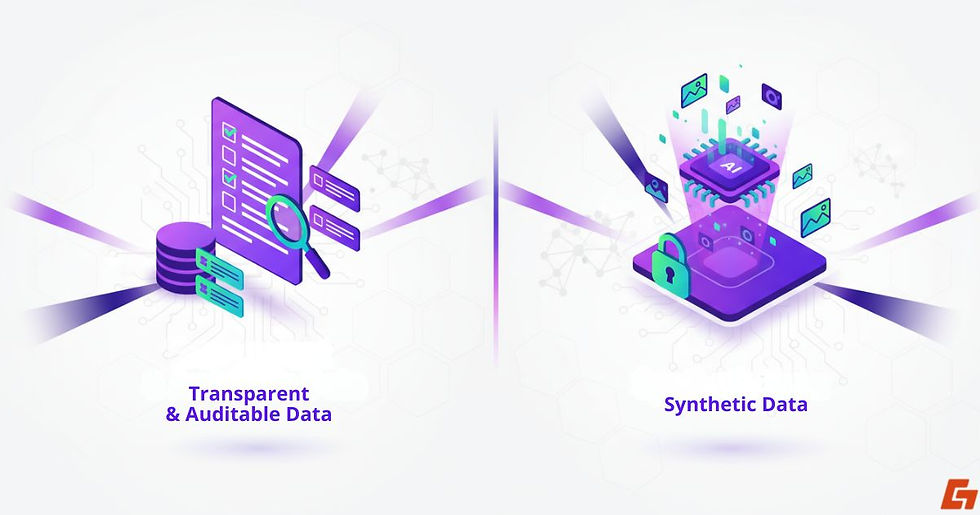
Transparent and Auditable Data Practices
One emerging trend is the creation of transparent and auditable datasets. These come with clear documentation explaining how the data was collected, who it represents, and what limitations it might have.
Initiatives like Datasheets for Datasets aim to make this process standard, so researchers and developers can make informed choices.
Synthetic Data: Filling Gaps and Protecting Privacy
Synthetic data is another rising star. By generating artificial but realistic examples, developers can reduce bias, fill gaps in representation, and protect privacy, especially when working with sensitive information like healthcare or financial records.
Why Ethics Go Beyond Compliance
Ethical dataset curation isn’t just about compliance with regulations; it’s about building AI systems that work fairly and reliably for everyone.
Where AI Datasets Come From and Why It Matters
AI datasets can be sourced from a wide variety of places, each with its own strengths and challenges.

Open Data Initiatives for Public Use
Platforms like Kaggle, Google Dataset Search, and Hugging Face Datasets offer thousands of free datasets covering everything from medical imaging to social media sentiment.
Government Databases: Reliable and Well-Documented
Agencies such as NASA, the US Census Bureau, and the EU Open Data Portal provide publicly available datasets, often highly accurate and backed by thorough documentation.
Corporate Datasets and the Privacy Debate
Tech companies like Google, Meta, and OpenAI frequently use enormous amounts of user-generated content to train their models, although this continues to spark debates around consent and privacy.
Choosing the Right Source for the Job
Whether the data comes from open repositories, government records, or corporate archives, the origin of your dataset will directly influence your AI model’s strengths and weaknesses.
While free and public datasets are great for experimentation, large-scale commercial projects often require custom-curated or proprietary data to meet specific performance goals. The source you choose will ultimately shape the AI’s capabilities and its limitations.
Why Strong AI Starts with Strong Data
We’ve explored what training datasets are, the different forms they take, and why their quality directly shapes the intelligence of AI systems. From labeling methods to ethical sourcing, every layer matters.
In the end, AI datasets aren’t just technical assets, they’re the foundation of every prediction, classification, and decision a model makes. Strong, fair, and diverse data builds AI we can actually rely on.
Next time you hear about a breakthrough in AI, ask yourself: what kind of data was behind it and was it good enough to trust the result?



Comments